Introduction
In robotics we often use occupancy grids to represent the environment and make decisions that affect our planning and other parts of our robotic stack. Occupancy grids are often a dense discretized view of the environment and take up a lot of time and resources if they are updated and utilized serially. This problem usually maps significantly better to the GPU, which can do all of the computations on the occupancy grid in parallel. But the well known mature frameworks like OpenCL and CUDA are focused on C programming using kernels in separate files, which can make it hard to produce customisable user friendly libraries for these sorts of problems. We will explore how SYCL, the C++ focused heterogeneous GPU programming framework, can help create libraries that are easy to use and can be user customized without compromising on speed. We’ll dive into the SYCL programming model and its ability to harness the parallel processing power of GPUs to handle large and complex datasets. We will demonstrate how SYCL can reduce the amount of code you have to write and make your processes faster with less effort. So, whether you’re building the next generation of autonomous vehicles or want to impress your friends with some high-tech perception wizardry, SYCL may be the way to go.
But first, we need a couple of things to ensure we are all on the same page. I will briefly introduce what a GPU is. We will also need a case study example of a “perception library”. We will use an “Occupancy Grid”, a very common approach for mobile robots to determine the state of the world and an algorithm that maps exceptionally well onto the GPU.
A GPU is a specialized processor designed for heterogeneous computing that can handle complex calculations in a vastly parallel manner, as opposed to a CPU which tends to do things serially. GPUs consist of many smaller processing units called cores (different frameworks refer to them differently, so we will just use “cores”) that can work in parallel to perform many computations simultaneously. While GPUs are commonly associated with visual processing, they are also well-suited for a wide range of applications in scientific computing, machine learning, and data analytics. In the case of perception libraries, which typically consist of vast amounts of information from LIDAR or images, this ability to run highly parallelized is a significant advantage.
An occupancy grid is a common way to discretise and simplify an environment into cells or voxels. In the image below, the world is segmented into three types of state, {Occupied, Free, Unknown}, represented by {Black, White, Grey}. This representation is a widespread way to view the environment and allows for outputs from the occupancy grid such as nearest obstacle, distance field transforms for planning and various visualisation outputs that could be viewed in a software like RVIZ.

Sundram, Jugesh & Nguyen, Harry Duong & Soh, Gim & Bouffanais, Roland & Wood, Kristin. (2018). Development of a Miniature Robot for Multi-robot Occupancy Grid Mapping. 10.1109/ICARM.2018.8610745.
The discretisation of the world into the grid allows for several benefits, including:
- The simple fusion of multiple sensor modalities like LIDAR, Range sensors, and Stereo vision based on the region of occupancy
- Largely parallelizable operations on individual grid cells.
Occupancy grids can, as aforementioned, be updated by a multitude of sensors. For simplicity, we will consider just a LIDAR. Updating an occupancy grid can have the following workflow:

Each of these processes is, luckily, fully parallelizable:
- By tracing a ray from the sensor to the point we can mark cells that we know as free space. Each ray can be processed using a core in the GPU.
- We can mark regions where points are as occupied. Each point can be handled in a GPU core.
- Decaying evidence is done per cell. Each cell can be decayed using a GPU core.
- Many of the outputs from the occupancy grid can also be generated using a massively parallelized approach.
So what is SYCL, and how does it help us? The SYCL (Standard for C++ Heterogeneous Programming) framework is a high-level C++ programming model designed to simplify the development of applications that can run on heterogeneous hardware, such as CPUs, GPUs, and other accelerators. SYCL offers several benefits over other popular frameworks, such as CUDA and OpenCL. One of the main advantages of SYCL is its ease of use, as it provides a standard C++ interface that enables developers to write code that is both portable and high-level. Additionally, SYCL provides better support for modern C++ features like templates and lambdas, making it a flexible and powerful option for developers.
In terms of performance, SYCL still needs to catch up with CUDA, however, it is being actively developed by Intel and other vendors such as Open SYCL. At SYCLCon 2022, Marcel Breyer presented his paper comparing the performance of SYCL against several other frameworks on several devices.
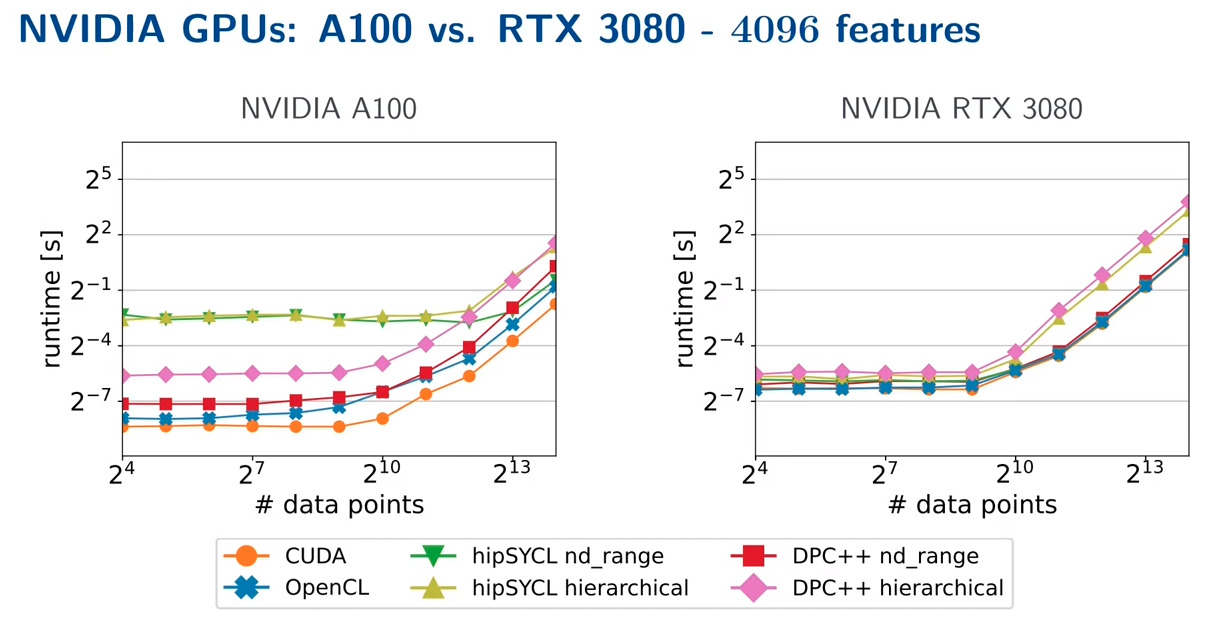
Marcel Breyer, Alexander Van Craen, and Dirk Pflüger. 2022. A Comparison of SYCL, OpenCL, CUDA, and OpenMP for Massively Parallel Support Vector Machine Classification on Multi-Vendor Hardware.
His advice suggests that SYCL should be used if you want to implement your code quickly and only once for multiple targeted GPU types and not when you need the most performance. I would add that if you want to create a user-facing library that is intended to be customized and is user-friendly, you should also consider SYCL.
Let’s take a simple example, like counting the number of cells in an occupancy grid, and see how we might implement it using SYCL instead of CUDA.
We would choose to represent occupancies in a class containing our grid:
class OccupancyGrid {
public:
// Various update functions, constructors, etc
size_t number_occupied(sycl::queue& device_queue) const;
private:
sycl::buffer<int, 2> occupancies; // In case of sycl
int* d_occupancies; // In case of CUDA
};
First we implement our function in CUDA:
// occupancy_grid_algorithms.cu
__global__ void countOccupiedCellsKernel(int* grid,
size_t width, size_t height, int* count) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int i = y * width + x;
if (grid[i] == 1) { atomicAdd(count, 1); }
}
}
// occupancy_grid.cpp
size_t OccupancyGrid::number_occupied() {
// Allocate memory for input and output data on the device
int* d_count;
cudaMalloc(&d_count, sizeof(int));
// Initialize output count to zero
int h_count = 0;
cudaMemcpy(d_count, &h_count, sizeof(int),
cudaMemcpyHostToDevice);
// Configure grid and block sizes for kernel launch
dim3 block(dim_x, dim_y);
dim3 grid((width + block.x - 1) / block.x,
(height + block.y - 1) / block.y);
// Launch kernel on device
countOccupiedCellsKernel<<<grid, block>>>(
d_occupancies, width, height, d_count);
// Copy result back from device to host and return count
cudaMemcpy(&h_count, d_count, sizeof(int),
cudaMemcpyDeviceToHost);
cudaFree(d_grid);
cudaFree(d_count);
return h_count;
}
In this code, you will note a couple of things that SYCL can help with:
- Direct resource management instead of self handling wrapper classes
- Separate files are needed between kernel and main C++ implementation
- Direct calculation of kernel indices
Now, some libraries can help with some of these things in CUDA. But SYCL just does this natively. The code that you write is expressive and easy to read. The objects are all just that, self-contained, lifetime managed objects.
Our implementation in SYCL might look like this:
size_t OccupancyGrid::number_occupied(sycl::queue& device_queue) const {
size_t count = 0;
sycl::buffer<1, size_t> count_buf{&output};
// Submit a kernel to the requested device
device_queue.submit([this, count_buf](sycl::handler& cgh)) {
// Get access to the data for the device
auto occupancy_accessor =
occupancies.get_access<sycl::access_mode::read>(cgh);
auto count_accessor =
count_buf.get_access<sycl::access_mode::write>(cgh);
// Run our kernel in parallel
cgh.parallel_for(occupancies.get_range(),
[occupancy_accessor, count_accessor](sycl::id<2> idx) {
// If the cell we are considering is above the occupancy
// threshold, increment our count
if (occupancy_accessor[idx] > occupancy_threshold) {
// We use an atomic to increment so we are thread safe
sycl::atomic count_atomic{count_accessor[0]};
count_atomic++;
}
});
}).wait();
return count;
}
This is it. It can be even simpler using some of the reduction libraries available as part of SYCL natively. CUDA will likely be faster, so looking nicer and using C++ correctly may not be enough to want to risk that high performance. But now let’s imagine that we want to add some more functions. Let’s say we want to count occupied in a specific segment of the occupancy grid. Then, we want to check all the occupied cells to see if there are clusters of cells next to each other. Then we want to….
Well, our class is quickly going to grow:
class OccupancyGrid {
public:
// Various update functions, constructors, etc
size_t number_occupied(sycl::queue& device_queue) const;
size_t number_occupied_in_sector(sycl::queue& device_queue, Point lower_sector, Point upper_sector);
size_t number_of_custered_cells(sycl::queue& device_queue);
// ... 100 more functions
This is poor design, we are producing a library. Not everyone that uses this library will need all these functions in this polluted interface. Not to mention that in CUDA, we may have to add more and more specific kernel functions for these. We could expose the internals of the occupancy grid class so that people can access it, and write some of the required functionality themselves,but this is a poor design. We want to be able to hide our internal implementation but, at the same time, allow a user to run custom kernel code on our occupancy grid data. Is there a way we can get both? Well, with SYCL, yes. Provide the user convenience operator functions so they can operate on the grid with a functor of their choosing:
sycl::buffer my_data;
auto my_kernel = [](sycl::id<2> occupied_id, sycl::accessor my_accessor) {
// Do something based on the occupied cell
}
// ...
my_occupancy_grid.apply_all_occupied(queue, my_kernel, AccessCreator{my_data});
If this was possible, the user could write their occupancy counting function:
size_t count = 0;
sycl::buffer<1, size_t> count_buf{&output};
auto counting_kernel = [](sycl::id<2>, sycl::accessor count_accessor) {
sycl::atomic count_atomic{count_accessor[0]};
count_atomic++;
};
my_occupancy_grid.apply_all_occupied(queue, counting_kernel, AccessCreator{count_buf});
Look how easy that is. But is it possible? Probably not in C or even C++, with regular kernels provided by CUDA. But with SYCL, why not? We have access to templates:
/**
* @brief Run a custom function on all of the occupied cells in the
* occupancy grid
*
* @tparam TFunctor the user function. Must be a functor object
* copyable to the device.
* @tparam TArgFunctors user provided conversion operators that get the
* data that the user function uses for the device
*
* @param queue the Device to run this on
* @param function the user function
* @param arg_functors the user data functions for converting data
*/
template < typename TFunctor, typename...TArgFunctors >
void OccupancyGrid::apply_all_occupied(
sycl::queue & queue,
TFunctor && function,
TArgFunctors && ...arg_functors
) const {
// Add a kernel to the queue
queue.submit(
[this, &function, &arg_functors...](sycl::handler & cgh) {
// Get the accessor for the occupancy grid
auto occupancy_accessor =
occupancies.get_access < sycl::access_mode::read > (cgh);
// The special intermediate function so we can run the user function
// and convert all the user data in the function call below.
auto run_parallel_for = [ & cgh, this, & function, occupancy_accessor]
(auto && ...args) {
// Actually run the kernel on the device.
cgh.parallel_for(
occupancies.get_range(),
[ = ](sycl::id < 2 > id) {
auto grid_cell = grid_accessor[id];
if (grid_cell > occupancy_threshold) {
// IFF the cell is occupied, call the user function.
function (id, args...);
}
}
);
};
// Run the user kernel, while using the Argument Functors to convert the
// user arguments to something usable for the kernel.
run_parallel_for(std::forward < TArgFunctors > (arg_functors)(cgh)...);
).wait();
}
Yeah, this looks complex, and it is, but it is so easy to use. As in the above examples, the user can easily submit any type of computation on the grid they want. This can be extended for all cells. You can make free functions without exposing the internal values of the grid or compromising the customizability. What a combo!
Another benefit that may surprise you is that the compiler has access to the full implementation of both the kernel and the outer C++ code. This means that the fancy O3 compiler optimisations that run on your normal C++ code may also run on your kernel code. This can mean that you get a serious speed up without getting into the nitty gritty of restricting pointers or re-arranging lines of C code in your kernels. Not to mention that if I want to use this in parallel on a CPU, or a different (supported) GPU, I don’t have to rewrite a single line of code or even re-compile!
We have discussed GPUs and how they might be used together with the SYCL framework to make fast, customizable, well written perception libraries for problems like an occupancy grid.There are many other robotics problems that could be solved with GPUs. If you are planning a project where you may be interested in doing parallel computing, especially on a GPU, keep SYCL in mind.
If you would like to delve deeper, here are some resources:
- Khronos SYCL home page
- GPU Performance Portability Using Standard C++ with SYCL - Hugh Delaney & Rod Burns - CppCon 2022
- A Comparison of SYCL, OpenCL, CUDA, & OpenMP for Massively Parallel Support Vector Classification - SyclCon 2022
- Open SYCL compiler
- Intel DPC++ Compiler
About the author
Ben Dart is a senior software engineer and roboticist with more than a decade of experience in both. Ben is passionate about software and wants to start using his skills to reduce emissions and increase safety of work across a wide variety of industries.
Sponsors
